
Cách lấy danh sách ngẫu nhiên không trùng lặp trong Excel
Trong quá trình hỗ trợ học viên và một số khách hàng, một vấn đề mà các bạn rất hay hỏi đó là làm thế nào để có thể lấy được một danh sách không trùng lặp ngẫu nhiên trong Excel. Trong bài viết lần này, chúng ta sẽ cùng nhau đi tìm hiểu giải pháp cho vấn đề này có thể áp dụng cho tất cả các phiên bản Excel 365, Excel 2019, Excel 2016, Excel 2013 và các phiên bản trước đó.
Bài viết này có kèm theo một video hướng dẫn ở cuối phần cuối.
Xem nhanh
Cách lấy danh sách ngẫu nhiên không trùng lặp trong Excel
Lưu ý Cách này chỉ hoạt động trên phiên bản Excel 365 có hỗ trợ các hàm mảng động
Để tạo ra một danh sách ngẫu nhiên không trùng lặp trong Excel, thì công thức chung của chúng ta như sau
INDEX(SORTBY(cột_dữ_liệu, RANDARRAY(ROWS(cột_dữ_liệu))), SEQUENCE(n))
Trong đó:
– cột_dữ_liệu là cột dữ liệu nguồn
– n là số lượng ô dữ liệu bạn cần lấy

Hãy cùng nhau đi thử công thức này cho trường hợp sau đây:
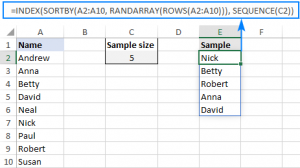
Trong hình minh họa trên, chúng ta sẽ đi lấy 5 giá trị ngẫu nhiên không trùng lặp của các tên trong cột A, chúng ta sẽ áp dụng công thức như sau:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(5))
Để tiện dụng cho việc thay đổi số lượng giá trị ngẫu nhiên lấy ra, chúng ta có thể thay số 5 trong công thức trên bằng tham chiếu tới ô C2, và công thức bây giờ của chúng ta trở thành:
=INDEX(SORTBY(A2:A10, RANDARRAY(ROWS(A2:A10))), SEQUENCE(C2))
Công thức này hoạt đông như thế nào?
Để hiểu được công thức trên hoạt động thế nào, chúng ta hãy đi từ trong ra ngoài như cách làm với những công thức Excel khác:
– Hàm RANDARRAY sẽ tạo ra một mảng các số ngẫu nhiên dựa vào giá trị trả về của hàm ROWS()
– Hàm SORTBY sẽ sắp xếp các giá trị ngẫu nhiên được trả về này
– Hàm INDEX sẽ lấy số lượng các giá trị ngẫu nhiên do chúng ta chỉ định bởi hàm SEQUENCE
Cách lấy nhiều dòng ngẫu nhiên không trùng lặp trong Excel
Lưu ý Cách làm này chỉ áp dụng cho phiên bản Excel 365
Để lấy ra nhiều dòng ngẫu nhiên không trùng lặp trong Excel, chúng ta có thể lấy theo một công thức chung như sau:
=INDEX(SORTBY(data, RANDARRAY(ROWS(data))), SEQUENCE(n), {1,2,…})
Trong đó:
– n là số dòng ngẫu nhiên không trùng lặp cần lấy ra
– {1,2,…} là số thứ tự các cột cần lấy dữ liệu về
Chúng ta hãy cùng đi áp dụng công thức trên cho bảng tính trong ví dụ sau đây:
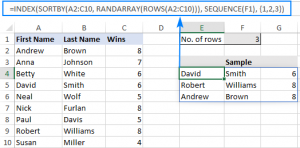
Áp dụng công thức tổng quát của chúng ta và thay các vùng giá trị, chúng ta có công thức sau đây:
=INDEX(SORTBY(A2:C10, RANDARRAY(ROWS(A2:C10))), SEQUENCE(F1), {1,2,3})
Cách công thức này hoạt động như thế nào?
Công thức này có logic giống như công thức ở trong phần trước của bài viết, chỉ khác một chi tiết nhỏ là chúng ta sẽ sử dụng hàm INDEX với một bộ tham số khác, tham số row_num sẽ nhận giá trị từ hàm SEQUENCE và column_num sẽ nhận ra trị từ mảng thứ tự của các cột.
Cách lấy giá trị ngẫu nhiên không trùng lặp trong Excel 2010 – 2019
Bởi vì chỉ Excel 365 mới có thể sử dụng những hàm mảng động, nên kiến thức trong hai phần trên sẽ không áp dụng được cho các phiên bản Excel từ Excel 2019 trở về trước.
Chúng ta vẫn có thể giải quyết vấn đề này như sau:
- Trong cột B của ví dụ minh họa, chúng ta sẽ sử dụng hàm RAND() cho các ô từ B2 tới B10
- Trích xuất ra giá trị ngẫu nhiên đầu tiên với công thức sau đây trong ô E2:
=INDEX($A$2:$A$10, RANK.EQ(B2, $B$2:$B$10) + COUNTIF($B$2:B2, B2) - 1) - Copy công thức trong E2 cho số dòng tương ứng với số giá trị ngẫu nhiên bạn muốn lấy ra từ danh sách. Nếu bạn muốn 3 giá trị ngẫu nhiên không trùng lặp, bạn kéo công thức từ E2 cho tới ô E4. Nếu muốn 4 giá trị ngẫu nhiên không trùng lặp, chúng ta kéo công thức từ E2 tới E5
Và kết quả nhận được sẽ là:
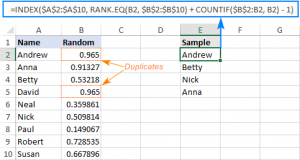
Công thức này hoạt động thế nào?
Đầu tiên, hàm RAND() trong cột B sẽ cho chúng ta một danh sách các số ngẫu nhiên, tuy nhiên, như bạn thấy ở trong ảnh ví dụ trên, thì danh sách này mặc dù được tạo ra một cách ngẫu nhiên bằng hàm RAND(), nhưng vẫn có khả năng có số trùng nhau. Chúng ta sẽ đi giải thích cách chúng ta kết hợp hàm để có thể giải quyết vấn đề này.
Hàm RANK.EQ sẽ tính toán thứ hạng (rank) của các con số trong cột B ở mỗi dòng. Ví dụ, trong ô E2, RANK.EQ(B2, $B$2:$B$10) sẽ sắp xếp thứ hạng của giá trị trong ô B2, so sánh với giá trị trong vùng B2:B10. Khi công thức này được copy xuống E3, bởi vì B2 được tham chiếu tương đối (không có ký tự $ trong địa chỉ tham chiếu), vậy nên, B2 chuyển thành B3 và công thức sẽ trả về thứ hạng của B3, …
Hàm COUNTIF sẽ giúp bạn đếm số lần một con số xuất hiện trong vùng dữ liệu. Ví dụ, trong công thức ở ô E2, COUNTIF($B$2:B2, B2) sẽ kiểm tra xem có bao nhiêu giá trị trong ô B2 trong vùng $B$2:B2, tất nhiên nhìn vào đây các bạn sẽ thắc mắc vì sao chúng ta lại viết như vậy, trông có hơi buồn cười không? Câu trả lời là có và không, bởi vì với kỹ thuật này, khi tham chiếu ô thay đổi lúc bạn kéo công thức xuống phía dưới, thì vùng đếm bởi hàm COUNTIF cũng thay đổi theo. Khi bạn kéo công thức xuống tới E5, thì công thức COUNTIF($B$2:B5, B5) sẽ đếm số lần xuất hiện của giá trị trong ô B5 trong vùng B2:B5.
Với công thức COUNTIF như trên, nếu giá trị trong cột B chỉ xuất hiện 1 lần, thì kết quả của hàm sẽ là 1; chúng ta sẽ trừ đi 1 đơn vị để giữ thứ hạng được tạo ra bởi hàm RANK.EQ. Nếu hàm COUNTIF trả về kết quả là 2, tương ứng với việc có 2 kết quả trùng lặp, thì chúng ta cũng trừ đi 1 để tăng kết quả thứ hạng lên, để đảm bảo không bị trùng lặp trong thứ hạng.
Trong ví dụ trên, với công thức trong ô E2 thì hàm RANK.EQ sẽ trả về kết quả là 1. Vì đây là giá trị đầu tiên, hàm COUNTIF cũng sẽ trả về kết quả là 1. RANK.EQ và COUNTIF sẽ cho kết quả bằng 2. Chúng ta trừ đi 1 đơn vị, như vậy thứ hạng sẽ trở về 1.
Bây giờ chúng ta sẽ xem, việc gì sẽ xảy ra khi có xuất hiện 2 giá trị trùng lặp bởi hàm RAND. Ví dụ trong ô B5, hàm RANK.EQ cho giá trị là 1 trong khi COUNTIF sẽ cho giá trị là 2. Tổng hai kết quả là 3, chúng ta trừ đi 1 sẽ được 2, và 2 cũng chính là thứ hạng của giá trị trong ô B5.
Thứ hạng được tính toán ra bởi sự kết hợp giữa hàm RANK.EQ và hàm COUNTIF sẽ được đưa vào tham số row_num của hàm INDEX. Hàm INDEX sẽ nhận nhiệm vụ lấy ra dòng tương ứng. Đây là lý do tại sao, chúng ta không thể có 2 dòng có cùng thứ hạng (cùng Rank), bởi vì khi đó hàm INDEX sẽ lấy ra giá trị bị trùng lặp.
Làm thế nào để Excel không thay đổi các giá trị ngẫu nhiên
Trong Excel, tất cả các hàm dữ liệu ngẫu nhiên như RAND, RANDBETWEEN và RANDARRAY đều sẽ được tính toán lại với mỗi sự thay đổi trên Worksheet. Do vậy, nếu bạn muốn Excel không phải tính toán quá nhiều, gây chậm file, bạn có thể chuyển dữ liệu sau khi tính toán thành dạng Value bằng cách copy toàn bộ dữ liệu, sau đó chọn ô sẽ đổ dữ liệu ra trên file Excel, bấm chuột hải, chọn Paste Special > Values.
Hi vọng với nội dung này, bạn có thể giải quyết được vấn đề lấy ra danh sách ngẫu nhiên không trùng lặp trong Excel của bạn. Nếu bạn chưa hiểu, hãy thử theo dõi video sau đây của Thanh:


Khóa học mới xuất bản










