
Sử dụng hàm MAP đếm tần suất xuất hiện giá trị tăng tiến
Giả sử ta có một dãy [“a”;”b”;”c”;”b”;”a”], làm thế nào để đếm tần suất xuất hiện giá trị tăng tiến, hay nói cách khác, trả về một dãy [1;1;1;2;2]? Trong bài viết này, Học Excel Online sẽ hướng dẫn bạn sử dụng hàm MAP để làm điều trên.
Đếm tần suất xuất hiện giá trị tăng tiến
Ta có dữ liệu sau:
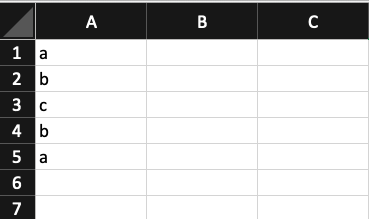
Trong thực tế, đôi khi ta sẽ cần đánh số thứ tự cho từng phần tử của một dãy. Ví dụ, giá trị a ở ô A1 xuất hiện lần đầu sẽ tương ứng với 1, ở ô A5 xuất hiện lần thứ hai sẽ tương ứng với 2… Áp dụng cho các giá trị b và c, mục tiêu ta trả về sẽ là một mảng 1,1,1,2,2:
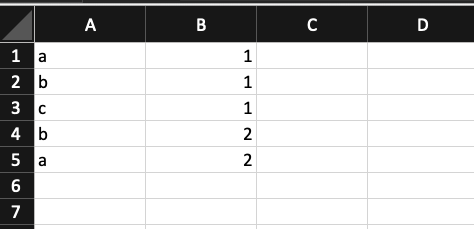
Ta hoàn toàn có thể làm điều này với hàm COUNTIF/COUNTIFS như sau tại ô B1:
=COUNTIF($A$1:A1;A1)
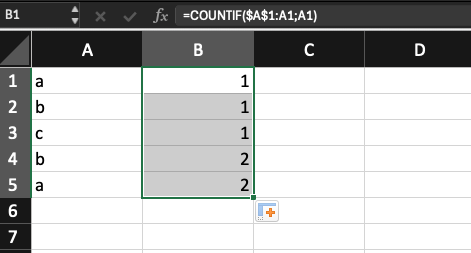
Một công thức vô cùng đơn giản phải không nào? Chúng ta sẽ “khoá” ô đầu tiên, sau đó tiến hành đếm các phần tử, từ đó thu được các giá trị tăng tiến.
Tuy nhiên, có một vấn đề với COUNTIF/COUNTIFS đó là chúng ta bắt buộc phải sử dụng tham chiếu. Nói cách khác, nếu dữ liệu của chúng ta là kết quả của một phép tính khác – một mảng được lưu trong bộ nhớ thay vì ghi vào ô – thì công thức trên sẽ không hoạt động.
Vậy giải pháp ở đây là gì?
Các bạn hãy tham khảo công thức sau:
=MAP(SEQUENCE(COUNTA({"a";"b";"c";"b";"a"}));LAMBDA(i;SUM(--(INDEX({"a";"b";"c";"b";"a"}; SEQUENCE(i)) = INDEX({"a";"b";"c";"b";"a"}; i)))))
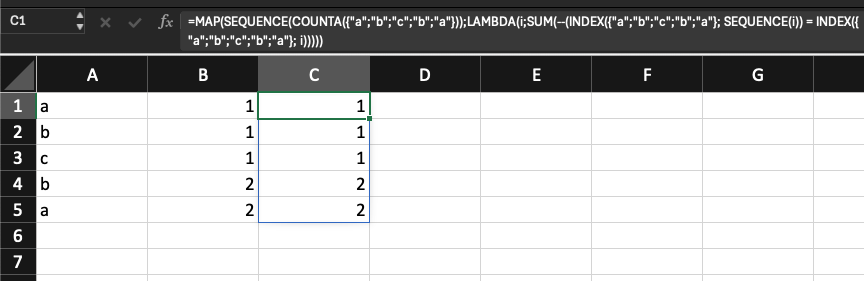
Trong công thức trên, tất cả được tạo ra và ghi vào bộ nhớ, không hề liên quan tới bất kỳ tham chiếu nào. Bởi vậy, ta có thể sử dụng để xử lý các dữ liệu từ những phép tính trước. Công thức trên có thể được diễn giải thành 2 bước:
$A$1:A1=A1; $A$1:A2=A2;$A$3:A3=A3;$A$4:A4=A4;$A$5:A5=A5
Kết quả của bước trên sẽ tạo những mảng con bao gồm:
{TRUE} – {FALSE;TRUE} – {FALSE;FALSE;TRUE} – {FALSE;TRUE;FALSE;TRUE} – {TRUE;FALSE;FALSE;FALSE;TRUE}
Và hàm SUM kết hợp phép biến đổi — sẽ biến TRUE thành 1, FALSE thành 0. Cộng TRUE với FALSE ta sẽ có 1;1;1;2;2.
Ứng dụng
Một trong những ứng dụng ở đây là kết hợp với hàm PIVOTBY. Trong Excel ta có hàm PIVOTBY giúp tạo ra bảng tương tự Pivot Table để tổng hợp và phân tích dữ liệu. Trong Pivot Table, tính năng Count Distinct (đếm không trùng lặp) chỉ khả dụng nếu bạn đưa dữ liệu vào trong Data Model. Với PIVOTBY kết hợp với hàm MAP trên, ta có thể trực tiếp tạo ra một phương thức tính toán Distinct Count, ví dụ:
=PIVOTBY(hàng;cột;giá trị;LAMBDA(x;LET(arr;VSTACK(x);filter_arr;MAP(SEQUENCE(COUNTA(arr));LAMBDA(i;SUM(--(INDEX(arr; SEQUENCE(i)) = INDEX(arr; i)))));COUNTA(FILTER(arr;filter_arr = 1 )))))Logic ở đây là ta sẽ tạo một bảng đếm tăng tiến, sau đó chỉ giữ lại những giá trị = 1 với hàm FILTER. Bằng cách này, ta sẽ đảm bảo được những giá trị thu về luôn là giá trị đầu tiên.
Ngoài ra, một cách khác để đếm giá trị không trùng lặp là dùng hàm UNIQUE:
=PIVOTBY(hàng;cột;giá trị;LAMBDA(x;COUNTA(UNIQUE(HSTACK(x)))))